Uploading binary data in ITK¶
Since every local Git repository contains a copy of the entire project history, it is important to avoid adding large binary files directly to the repository. Large binary files added and removed throughout a project’s history will cause the repository to become bloated, take up too much disk space, require excessive time and bandwidth to download, etc.
A solution to this problem which has been adopted by ITK is to store binary files, such as images, in a separate location outside the Git repository, then download the files at build time with CMake.
A “content link” file contains an identifying Content Identifier (CID). The content
link is stored in the Git repository at the path where the file would exist,
but with a .cid extension appended to the file name. CMake will find
these content link files at build time, download them from a list of server
resources, and create symlinks or copies of the original files at the
corresponding location in the build tree.
The Content Identifier (CID) is a self-describing hash following the multiformats standard created by the Interplanetary Filesystem (IPFS) community. A file with a CID for its filename is content-verifiable. Locating files according to their CID makes content-addressed, as opposed to location-addressed, data exchange possible. This practice is the foundation of the decentralized web, also known as the dWeb or Web3. By adopting Web3, we gain:
Permissionless data uploads
Robust, redundant storage
Local and peer-to-peer storage
Scalability
Sustainability
Contributors upload their data by running a small Python helper that packs
the file into a CARv1 using npx ipfs-car, uploads the CAR to a Filebase
IPFS bucket through Filebase’s S3-compatible REST API, records the resulting
CID in a manifest, and (optionally) mirrors the bytes into the ITKTestingData
GitHub Pages repository. A local Kubo daemon, IPFS Desktop, or any
ipfs pin remote PSA service is not required. See
Utilities/Maintenance/ExternalDataUpload/README.md for the one-time
developer setup and full workflow.
Data referenced from the ITK Git repository is stored across redundant locations so it can be retrieved from any of the following at build time:
Filebase IPFS gateway (where uploads land)
ITKTestingData GitHub Pages mirror
Public IPFS HTTP gateways (
ipfs.io,dweb.link,cloudflare-ipfs.com,gateway.pinata.cloud)Local Kubo gateway (typically
127.0.0.1:8080) when presentKitware’s Apache HTTP Server
Local
ExternalData_OBJECT_STOREScacheArchive tarballs from GitHub Releases
Historical ITKData DataLad repository snapshots (older content links)
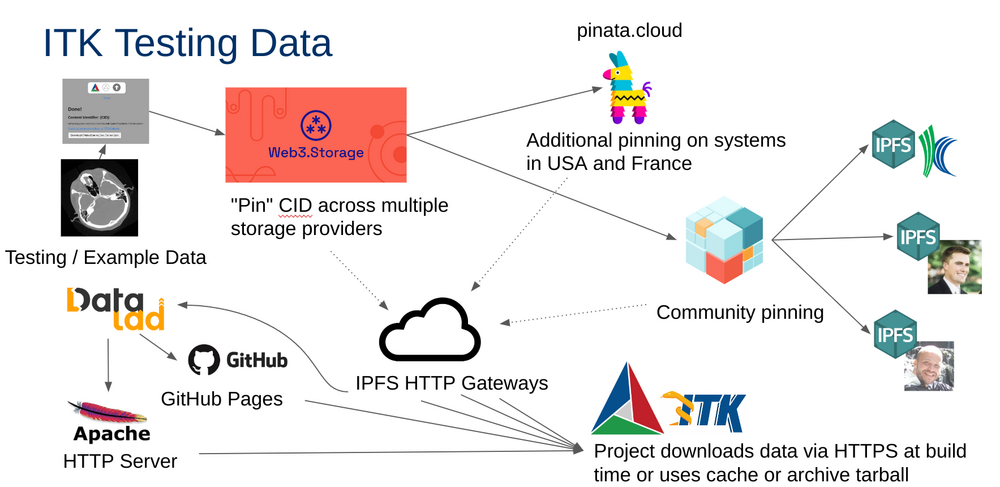
Testing data workflow. New content is added with the
Utilities/Maintenance/ExternalDataUpload/upload.py helper, which packs
the file into a CAR with npx ipfs-car (defaults match the
unixfs-v1-2025 / IPIP-0499 profile so CIDs are reproducible) and uploads
the CAR to a Filebase IPFS bucket via boto3 against Filebase’s
S3-compatible API. The CID Filebase reports back from head_object is
verified against the locally computed CID, written as a .cid content
link in the ITK source tree, and recorded in
Testing/Data/content-links.manifest. Files ≤ 50 MB can additionally be
mirrored into ITKTestingData for GitHub Pages CDN delivery. At test
time an ITK build can fetch the data from a local cache, archive tarball,
the Apache HTTP server, the GitHub Pages mirror, or any of several public
IPFS HTTP gateways.
See also our Data guide for more information.
Adding images as input to ITK sources¶
ITK examples and ITK class tests (see Section 9.4 of the ITK Software Guide) rely on input and baseline images (or data in general) to demonstrate and check the features of a given class. Hence, when developing an ITK example or test, images will need to be added to the Git repository.
When using images for an ITK example or test images, the following principles need to be followed:
Images should be small.
The source tree is not an image database, but a source code repository.
Adding an image larger than 50 Kb should be justified by a discussion with the ITK community.
Regression (baseline) images should not use Analyze format unless the test is for the
AnalyzeImageIOand related classes.Images should use non-trivial Metadata.
Origin should be different form zeros.
Spacing should be different from ones, and it should be anisotropic.
Direction should be different from identity.
Upload new testing data¶
One-time setup¶
The upload workflow needs:
The
external-data-uploadpixi environment installed (pixi install -e external-data-upload). It provides Python 3, boto3, and Node.js (which makesnpx ipfs-caravailable without a separate global install).A Filebase IPFS bucket and an S3 access key for that bucket. Filebase’s free tier is sufficient — the upload uses the S3 import-as-CAR path, not the legacy IPFS Pinning Service API.
The credentials exported as environment variables before running the helper:
export FILEBASE_ACCESS_KEY=...
export FILEBASE_SECRET_KEY=...
export FILEBASE_BUCKET=itk-data
The full step-by-step setup is documented in
Utilities/Maintenance/ExternalDataUpload/README.md. Complete that
one-time setup before proceeding.
Upload a file¶
From the ITK source tree, run the upload helper with the path to the file you want to upload:
pixi run -e external-data-upload python \
Utilities/Maintenance/ExternalDataUpload/upload.py \
Modules/.../test/Baseline/MyTest.png
The helper will:
Pack the file into a CARv1 with
npx ipfs-car pack --no-wrap— ipfs-car v1+ defaults to 1 MiB chunks, 1024 children per node, raw leaves, CIDv1, which is the unixfs-v1-2025 profile, so the CID is reproducible across implementations.PUT the CAR to your Filebase IPFS bucket with
x-amz-meta-import: carso Filebase imports it server-side, then read the imported CID back viahead_objectand verify it matches the locally computed CID.Replace
MyTest.pngin the source tree withMyTest.png.cid— a one-line text file containing the CID.Append the CID and source-tree path to
Testing/Data/content-links.manifest.Print the
git rm/git addcommands needed to stage the change.
Mirror to ITKTestingData (optional but recommended)¶
Pass --testing-data-repo <path> to additionally copy the file into a
local clone of ITKTestingData at CID/<cid>:
pixi run -e external-data-upload python \
Utilities/Maintenance/ExternalDataUpload/upload.py \
--testing-data-repo ~/src/ITKTestingData \
Modules/.../test/Baseline/MyTest.png
This populates the GitHub Pages mirror gateway
(https://insightsoftwareconsortium.github.io/ITKTestingData/CID/<cid>)
already listed in CMake/ITKExternalData.cmake. Commit and push in
the ITKTestingData repo to publish. Files larger than 50 MB are
skipped for the mirror step only (GitHub rejects pushes containing
files over 50 MB per file) — the Filebase upload still proceeds for
those files.
Alternative: upload via the web app¶
Contributors who prefer not to run any local tooling can upload a file
through the Content Link Upload web app (Alt Link). The app pins the
file and returns the corresponding .cid content link to download. The
resulting CID is usable anywhere the helper-produced CID would be — but
the manifest entry and the optional ITKTestingData mirror must then be
added by hand. The helper above is preferred when available because it
also updates Testing/Data/content-links.manifest in one step.
Normalize existing content links¶
Older .md5 / .sha256 / .sha512 content links can be converted to
.cid, and existing .cid links can be regenerated under the
unixfs-v1-2025 profile, with:
pixi run -e external-data-upload python \
Utilities/Maintenance/ExternalDataUpload/normalize.py <path-or-file>
See Utilities/Maintenance/ExternalDataUpload/README.md for the full
set of options (--dry-run, --hash-only, --cid-only,
--testing-data-repo, --bucket).
Add the content link to the source tree¶
The upload helper prints the exact commands to stage:
git rm path/to/MyTest.png
git add path/to/MyTest.png.cid
git add Testing/Data/content-links.manifest
git commit
Next time CMake configuration runs, it will find the new content link.
During the next project build, the data file corresponding to the
content link will be downloaded into the build tree from the first
reachable gateway in CMake/ITKExternalData.cmake.